require(Seurat)Loading required package: SeuratLoading required package: SeuratObjectLoading required package: sp
Attaching package: 'SeuratObject'The following objects are masked from 'package:base':
intersect, trequire(dplyr)Loading required package: dplyr
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionrequire(Yano)Loading required package: Yanoexp.1 <- ReadPISA("./visium/section1/Anterior/exp/", prefix = "sec1_ant_")
image.1 <- Read10X_Image("./visium/section1/Anterior/spatial/")
new.names <- paste0("sec1_ant_",Cells(image.1))
image.1 <- RenameCells(image.1, new.names = new.names)
## QuickRecipe() is actually an integration function of Seurat workflow
obj.1 <- QuickRecipe(exp.1[, Cells(image.1)], verbose = FALSE)
obj.1[['slice1']] <- image.1[colnames(obj.1),]
obj.1$orig.ident <- "sec1_ant"
exp.2 <- ReadPISA("./visium/section1/Posterior/exp/", prefix = "sec1_pos_")
image.2 <- Read10X_Image("./visium/section1/Posterior/spatial/")
new.names <- paste0("sec1_pos_",Cells(image.2))
image.2 <- RenameCells(image.2, new.names = new.names)
obj.2 <- QuickRecipe(exp.2[,Cells(image.2)], verbose = FALSE)
obj.2[['slice2']] <- image.2[colnames(obj.2),]
obj.2$orig.ident <- "sec1_pos"
exp.3 <- ReadPISA("./visium/section2/Anterior/exp/", prefix="sec2_ant_")
image.3 <- Read10X_Image("./visium/section2/Anterior/spatial/")
new.names <- paste0("sec2_ant_",Cells(image.3))
image.3 <- RenameCells(image.3, new.names = new.names)
obj.3 <- QuickRecipe(exp.3[, Cells(image.3)], verbose = FALSE)
obj.3[['slice3']] <- image.3[colnames(obj.3),]
obj.3$orig.ident <- "sec2_ant"
exp.4 <- ReadPISA("./visium/section2/Posterior/exp/", prefix="sec2_pos_")
image.4 <- Read10X_Image("./visium/section2/Posterior/spatial/")
new.names <- paste0("sec2_pos_",Cells(image.4))
image.4 <- RenameCells(image.4, new.names = new.names)
obj.4 <- QuickRecipe(exp.4[, Cells(image.4)], verbose = FALSE)
obj.4[['slice4']] <- image.4[colnames(obj.4),]
obj.4$orig.ident <- "sec2_pos"
# Merge all processed Seurat object
obj <- merge(obj.1, y = list(obj.2, obj.3, obj.4))
obj <- QuickRecipe(obj)Set default assay to RNAobject <- NormalizeData(object, normalization.method = "LogNormalize", scale.factor = 10000)Normalizing layer: counts.1Normalizing layer: counts.2Normalizing layer: counts.3Normalizing layer: counts.4object <- FindVariableFeatures(object, selection.method = "vst", nfeatures = 3000)Finding variable features for layer counts.1Finding variable features for layer counts.2Finding variable features for layer counts.3Finding variable features for layer counts.4object <- ScaleData(object, features = @features)Centering and scaling data matrixobject <- RunPCA(object, features = @featuresPC_ 1
Positive: Trf, Apod, Plekhb1, Mbp, Cnp, Plp1, Mobp, Car2, Mag, Dbi
Cryab, Mog, Cldn11, Bcas1, Sept4, Mal, Ndrg1, Ptgds, Gatm, Ermn
Qdpr, Ppp1r14a, Sparc, Gsn, Ugt8a, Gfap, Fa2h, Gm20425, Pllp, Tmem88b
Negative: Calm2, Ctxn1, Rtn1, Chn1, Nrgn, Syt1, Ppp3r1, Cx3cl1, Ptprn, Gria2
Gpm6a, Sept5, Ptk2b, Gp1bb, Enc1, Calm1, Fbxl16, Basp1, Arf3, Snca
Meg3, Camkv, Hpcal4, Syt5, Chst1, Nsg2, Icam5, Ppp3ca, Pld3, Dclk1
PC_ 2
Positive: Tmsb4x, Nrgn, Inf2, Ctxn1, Ngef, Gpr88, Gng7, Ddn, Adcy5, Pde1b
Camkv, Rgs9, Phactr1, Kcnip2, Klhl2, Ptk2b, Lrrc10b, Ptpn5, Tac1, Cx3cl1
Adora2a, Bcl11b, Efnb3, Crip2, Mal, Pde2a, Ppp1r1a, Tmem158, Basp1, Hpca
Negative: Cbln1, Car8, Neurod1, Pcp2, Gm2694, Ppp1r17, Lhx1os, Zic1, Nrep, Shf
Rgs8, Kcnc3, Grin2c, Ank1, Inpp5a, Homer3, Grm4, Pvalb, Kcnc1, Il16
Sphkap, Icmt, Calb2, Trim62, Gng13, Il20rb, Chn2, Pagr1a, Dusp5, Atp2a3
PC_ 3
Positive: Cck, Stmn1, Gnas, Nrn1, 3110035E14Rik, Slc17a7, Olfm1, Vsnl1, Tbr1, Lingo1
Stx1a, Slc30a3, Ncald, Dkk3, Efhd2, Rtn4r, Neurod6, Miat, 1110008P14Rik, Gm11549
Mpped1, Basp1, Pde1a, Gabbr2, Nsmf, Fxyd7, Syt13, Mical2, E130012A19Rik, Osbpl1a
Negative: Penk, Rgs9, Adora2a, Pde10a, Ppp1r1b, Gpr88, Drd1, Syndig1l, Gpr6, Tac1
Lrrc10b, Rxrg, Adcy5, Scn4b, Pde1b, Rasd2, Gng7, Rarb, Slc35d3, Tmem158
Actn2, Serpina9, Strip2, Slc32a1, Ankrd63, Kcnab1, Dmkn, Gnal, Pcp4l1, St8sia3
PC_ 4
Positive: Scn4b, Mbp, Slc24a2, Qdpr, Mobp, Mag, Bcas1, Nefm, Plp1, Mal
Plekhb1, Vamp1, Nefl, Sept4, Ermn, Tspan2, Mog, Arpp19, Trf, Cnp
Cryab, AI593442, Pex5l, Tmem88b, Gpr37, Ppp1r14a, Pllp, Uchl1, Kcnab1, Snap25
Negative: Igf2, Islr, Igfbp2, Slc13a4, Mgp, Fmod, Slc6a20a, Aebp1, Ogn, Nnat
Slc6a13, Col1a2, Fabp7, Aldh1a2, Rbp1, Gjb2, Pcolce, Slc22a6, Slc13a3, Bmp7
Dcn, Fn1, Serping1, Col1a1, Crabp2, Ifitm3, Efemp1, Bgn, Vim, Fbln1
PC_ 5
Positive: Itpr1, Itpka, Zbtb18, Cplx2, Adcy1, Rnf112, Nptx1, Lmo4, Hpca, Neurod2
Dkk3, Sptbn2, Camk4, Cnr1, Cnksr2, Arpp19, Fbxl16, Tmem132a, Igf2, Prkcb
Atp1a1, Dgkz, Lzts3, Mmp17, Ppp1r1b, Neurl1a, Slc8a2, Gas7, Slc13a4, Fam212b
Negative: Slc6a11, Gng4, Nrip3, Scg2, Ptpro, Sp8, Dlx1, Hap1, Cdhr1, Th
Doc2g, Zcchc12, Pcbp3, Pbx3, Scgn, Dcx, Tshz1, Tuba1a, A230065H16Rik, Tubb3
Cacng5, Pcp4l1, Cpne4, Lgr5, Lgr6, Sp9, Dlx2, Tmem130, Adamts19, Tubb2a object <- FindNeighbors(object, dims = 1:20)Computing nearest neighbor graphComputing SNNobject <- FindClusters(object, resolution = 0.5)Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 12148
Number of edges: 388028
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9315
Number of communities: 16
Elapsed time: 0 secondsobject <- RunUMAP(object, dims = 1:20)14:46:37 UMAP embedding parameters a = 0.9922 b = 1.11214:46:37 Read 12148 rows and found 20 numeric columns14:46:37 Using Annoy for neighbor search, n_neighbors = 3014:46:37 Building Annoy index with metric = cosine, n_trees = 500% 10 20 30 40 50 60 70 80 90 100%[----|----|----|----|----|----|----|----|----|----|**************************************************|
14:46:42 Writing NN index file to temp file /local/tmp/RtmpWPaWRY/file21c4cb60805922
14:46:42 Searching Annoy index using 1 thread, search_k = 3000
14:47:01 Annoy recall = 100%
14:47:01 Commencing smooth kNN distance calibration using 1 thread with target n_neighbors = 30
14:47:02 Initializing from normalized Laplacian + noise (using RSpectra)
14:47:16 Commencing optimization for 200 epochs, with 500526 positive edges
14:47:16 Using rng type: pcg
14:47:31 Optimization finishedp1 <- DimPlot(obj, group.by = "orig.ident")
p2 <- DimPlot(obj)
p1 + p2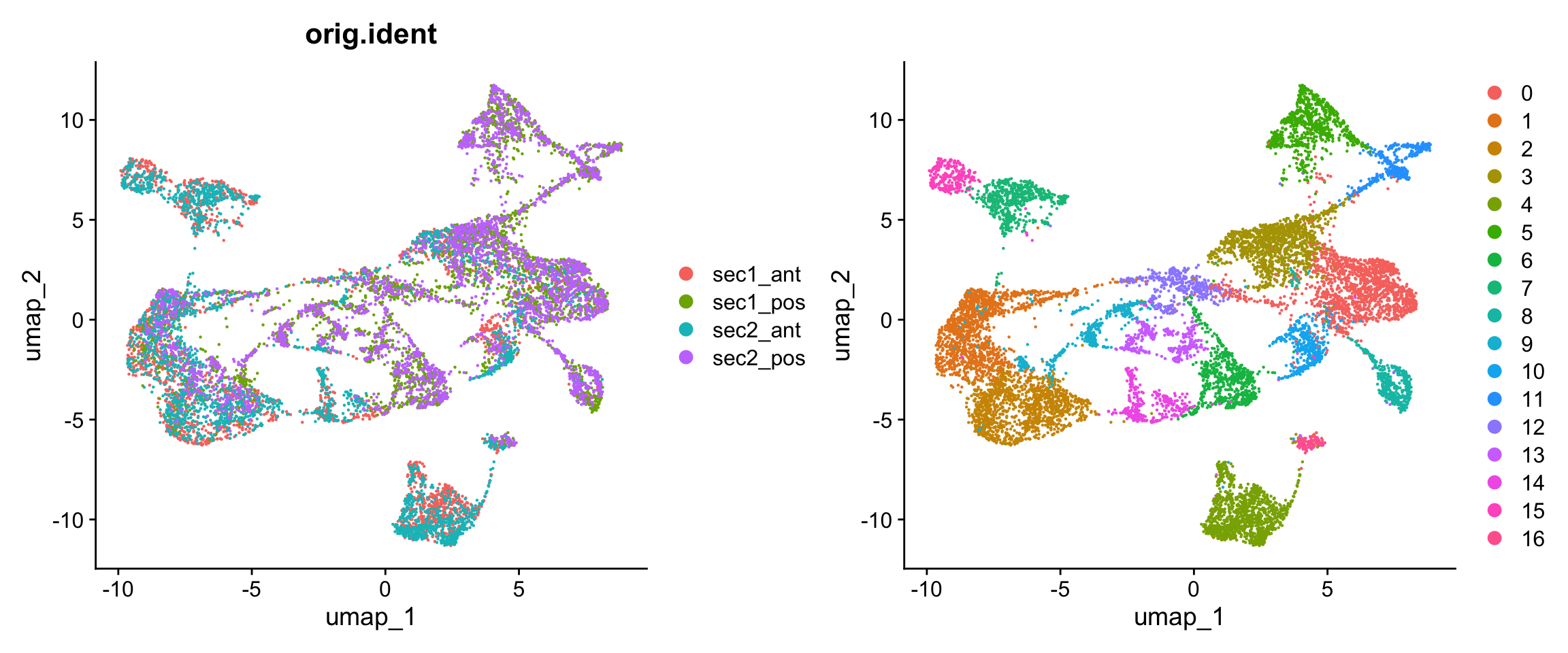
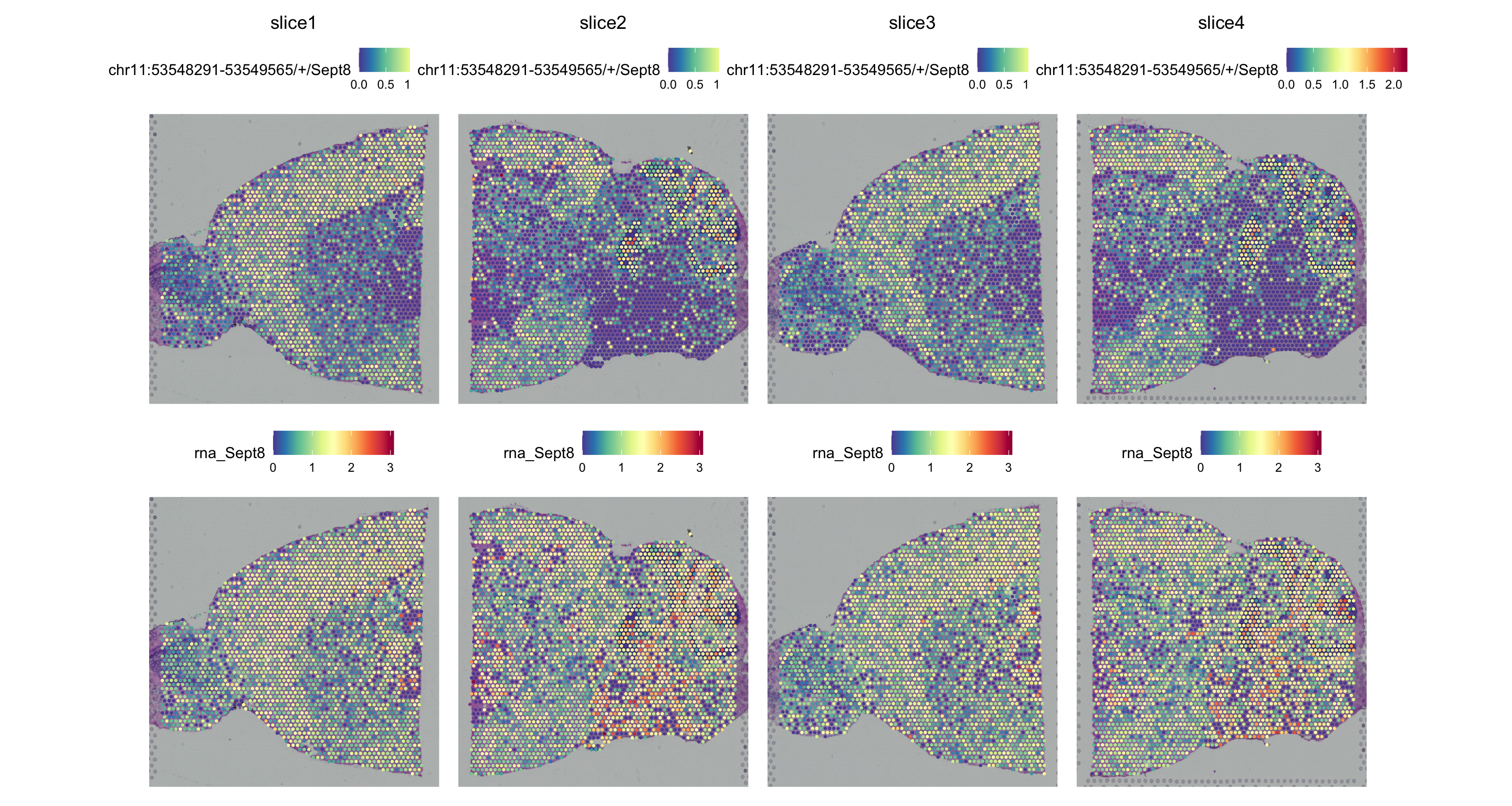
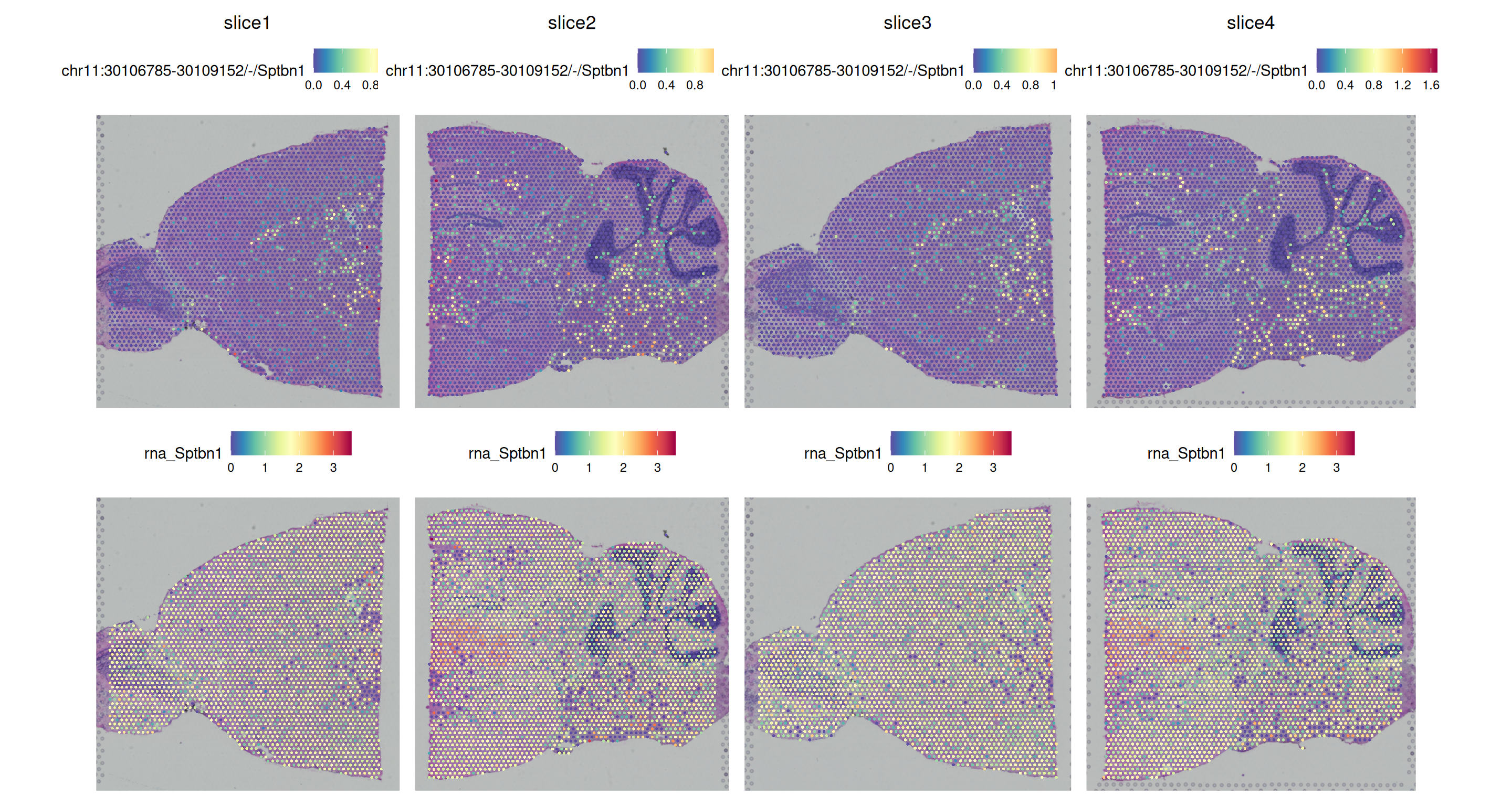
SpatialPlot(obj, pt.size.factor = 2) 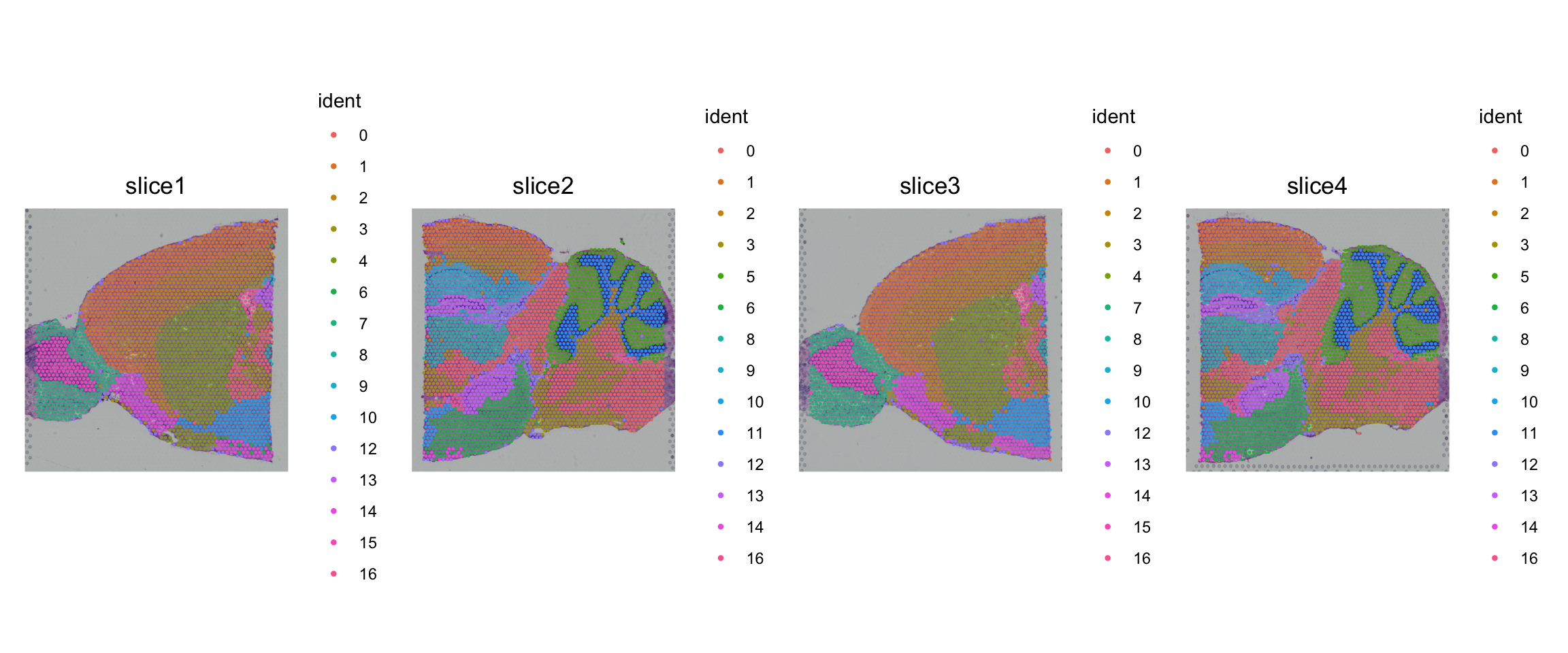
exon.1 <- ReadPISA("./visium/section1/Anterior/exon/", prefix = "sec1_ant_", cells = Cells(obj))
exon.2 <- ReadPISA("./visium/section1/Posterior/exon/", prefix = "sec1_pos_", cells = Cells(obj))
exon.3 <- ReadPISA("./visium/section2/Anterior/exon/", prefix = "sec2_ant_", cells = Cells(obj))
exon.4 <- ReadPISA("./visium/section2/Posterior/exon/", prefix = "sec2_pos_", cells = Cells(obj))
exon <- mergeMatrix(exon.1, exon.2, exon.3, exon.4)'as(<dgTMatrix>, "dgCMatrix")' is deprecated.
Use 'as(., "CsparseMatrix")' instead.
See help("Deprecated") and help("Matrix-deprecated").obj[['exon']] <- CreateAssayObject(exon[, Cells(obj)], min.cells = 20)
DefaultAssay(obj) <- "exon"
obj <- NormalizeData(obj)
obj <- ParseExonName(obj)Working on assay exonobj <- RunAutoCorr(obj)Working on assay : exon
Run autocorrelation test for 80178 features.
Runtime : 20.818 secs
38784 autocorrelated features.obj <- RunSDT(obj, bind.name = "gene_name", bind.assay = "RNA")Working on assay exon.
Working on binding assay RNA.
Use predefined weight matrix "pca_wm".
Processing 38784 features.
Processing 15696 binding features.
Retrieve binding data from assay RNA.
Use "data" layer for test features and binding features.
Using 95 threads.
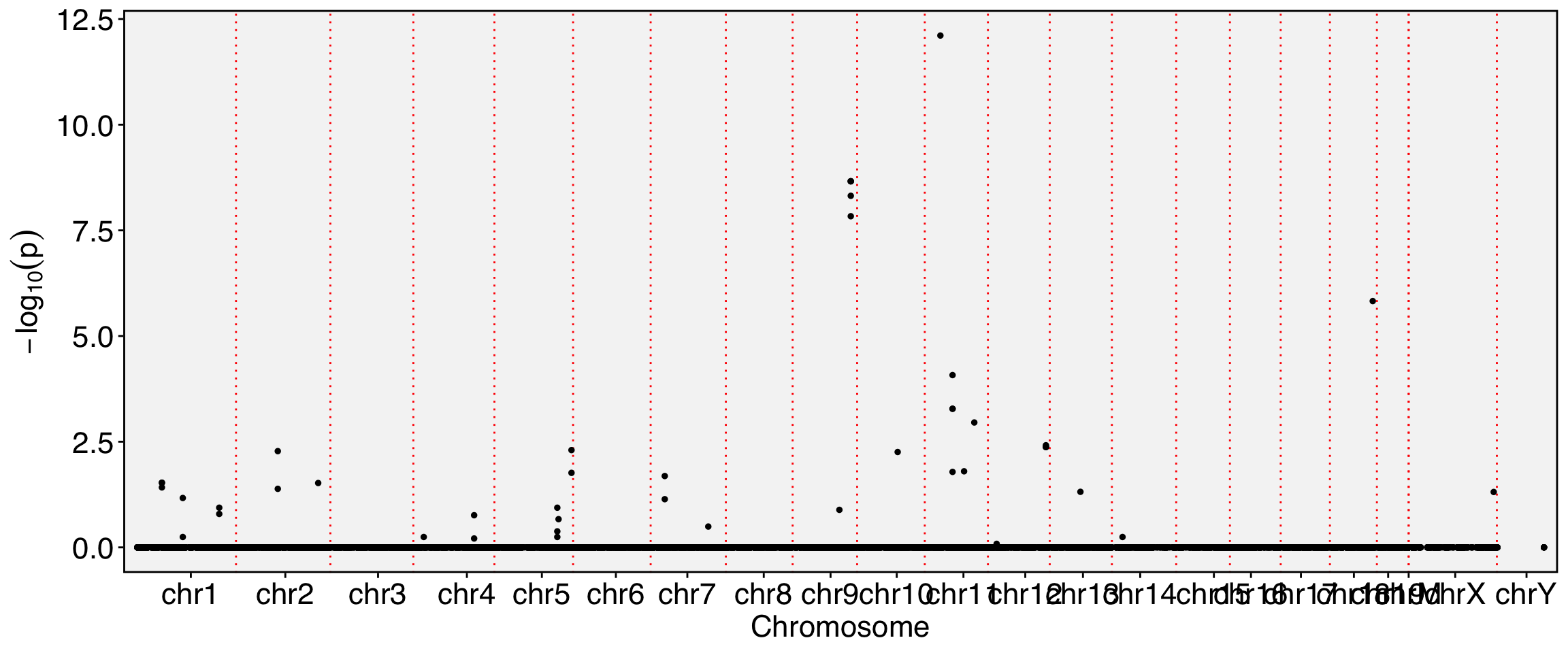
Runtime : 2.730924 mins.FbtPlot(obj, val = "gene_name.padj")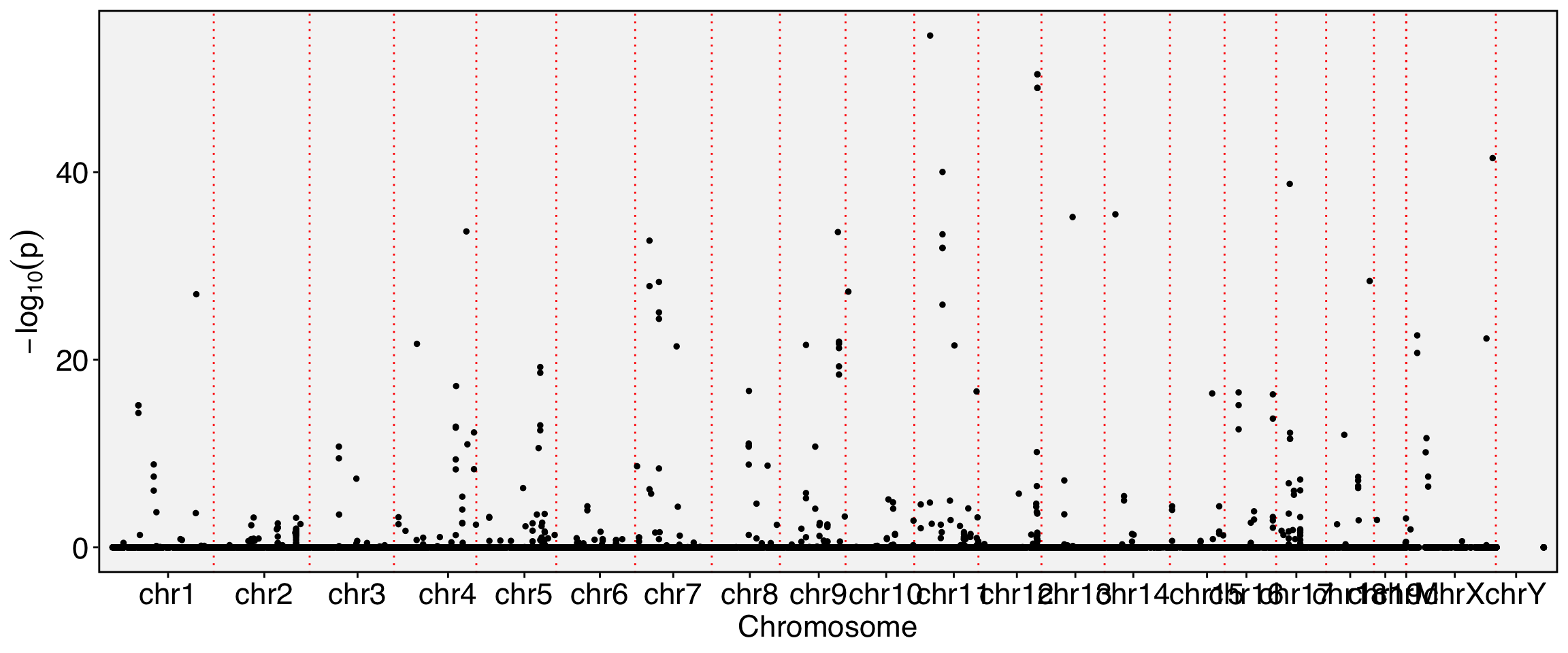
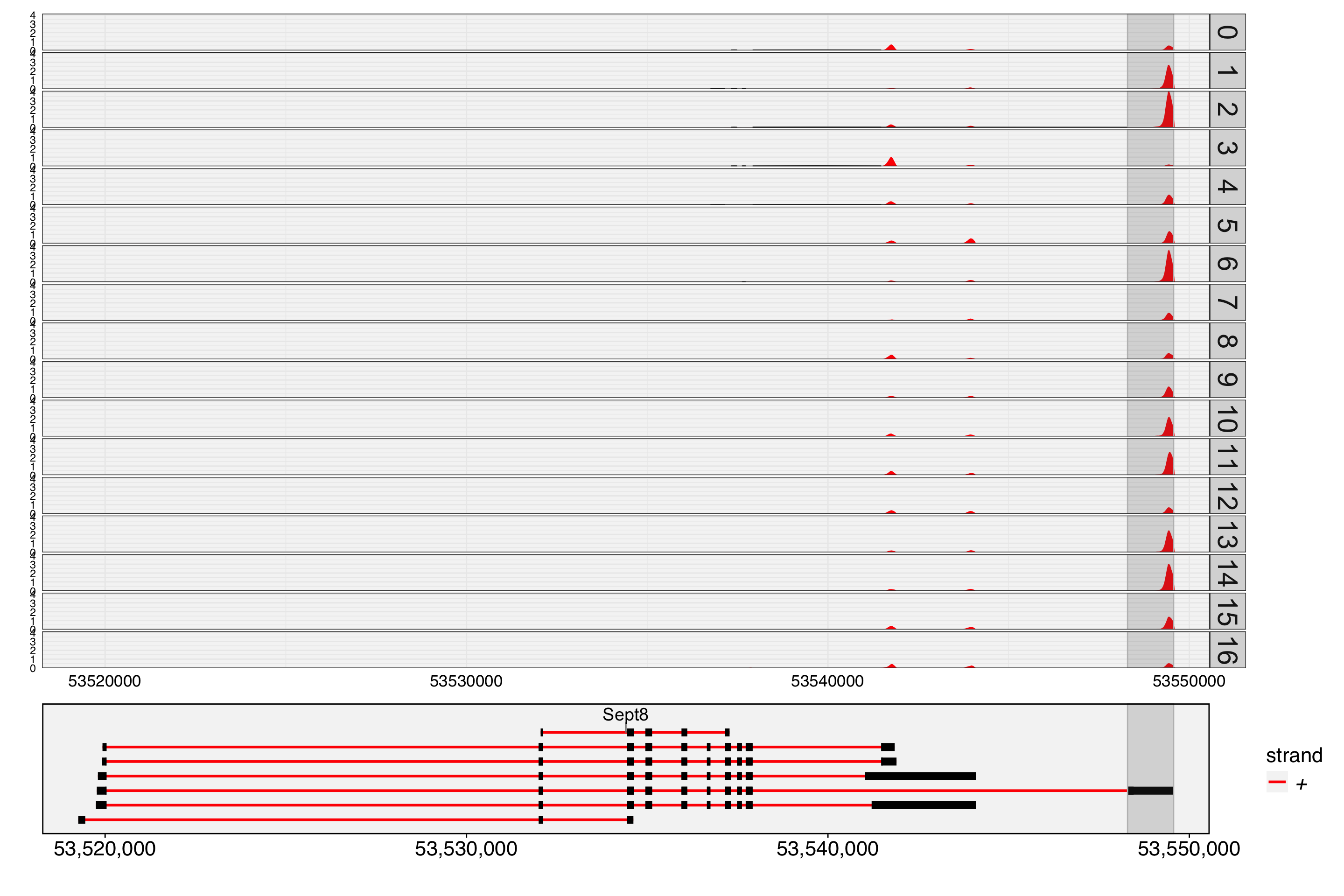
obj[['exon']][[]] %>% filter(gene_name.padj<1e-10) %>% DT::datatable()